















I have to admit that historically, I am not a big fan of unit testing. Not in a sense that I don't like testing as such: it is just that my experience shows that other kinds of automated testing (such as simulation testing and replay testing) happen to be much more useful in making programs more robust so that IMNSHO at most 20% of overall testing efforts should go towards the unit testing.1
1 well, this stands only for statically-typed programming languages, and is different for dynamically-typed ones, but this is a separate and quite long topic which deserves a different article
Re-Using Research Data to Come Up with a Completely Different Interpretation
Recently, I ran into an interesting research Dietrich; in the article, the author takes 100 open-source C# projects, and runs certain statistics over them. For example, there is a graph which shows "dependency of percentage-of-public-methods on the percentage-of-methods-being-unit-test-methods". And a graph of "dependency of cyclomatic complexity on the percentage-of-methods-being-unit-test-methods". And so on and so forth.
When looking at those graphs, I got a very clear feeling of what they IMNSHO really indicate; however, my interpretations were very different from the author's interpretations of the very same data. So, what I am going to do, is to re-use his data - while providing another (and IMNSHO much better 😉 ) interpretation.
The Data
Most of the data in Dietrich were related to what is often considered different metrics of code quality, in particular:2
- percentage of public methods (generally, the more encapsulation we have - the better)
- average method length (LOC). It is often argued that methods should be short.
- cyclomatic complexity (CC). For the explanation of cyclomatic complexity, see, for example, Dietrich.Cyclomatic
- number of overloads (too many overloads tend to decrease readability; while it is arguable, let's keep it to see if it changes anything)
I took these four graphs from Dietrich, normalized them (so the integral under the graph is 1 for all the data series), turned them where necessary so that for all of them are "higher is better", and centered them around zero so that zero corresponds to the average value for each of the metrics. Here is what I got as a result:
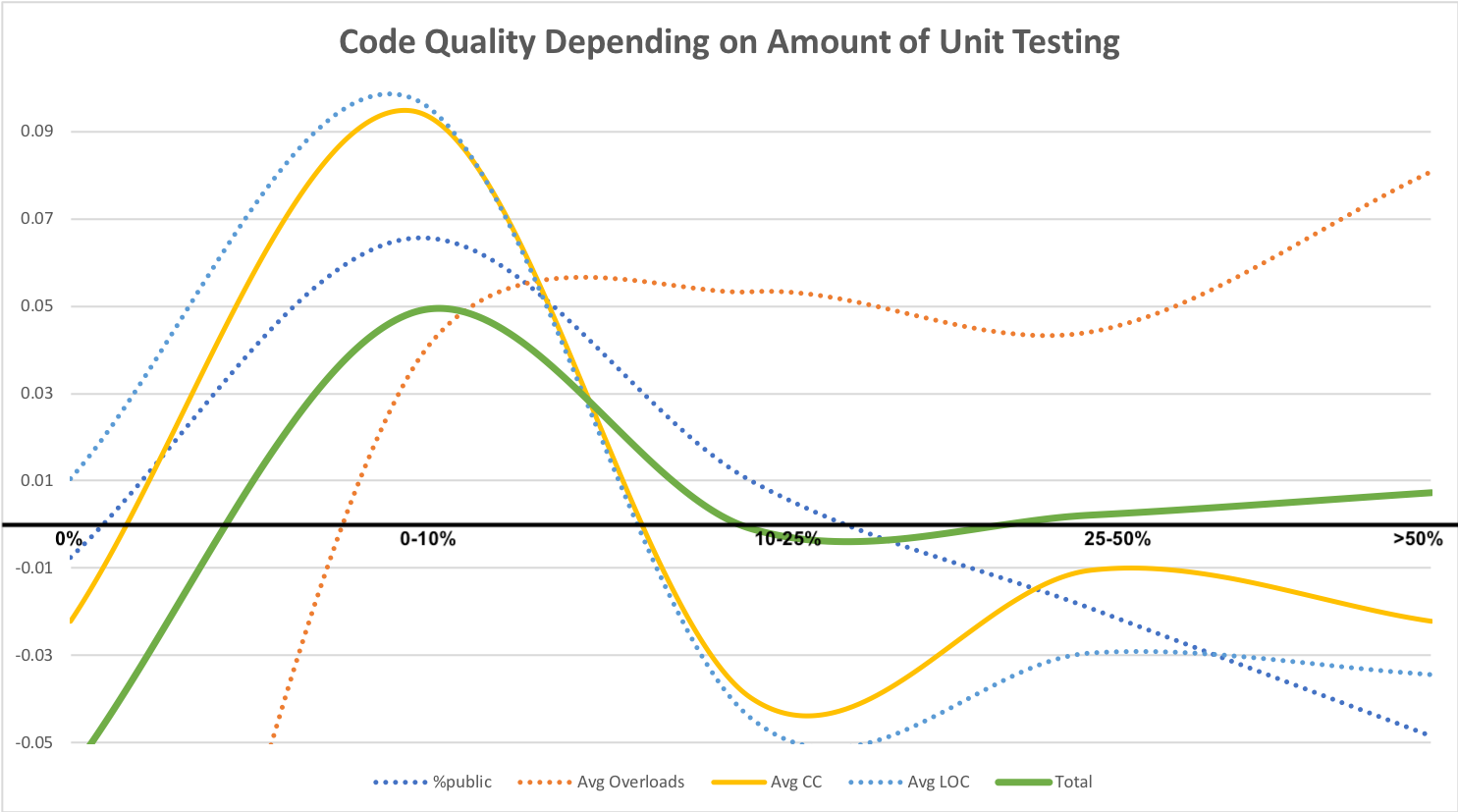
On this graph, just as in Dietrich, horizontal axis represents the percentage of unit testing methods to overall number of methods. And on the vertical axis, there are different metrics of what-is-often-considered-beneficial-to-code-quality.
And as we can see, 3 out of 4 code quality graphs - as well as total one - look pretty much the same:
Code quality tends to be Quite Bad(tm) when there is no unit testing at all,
reaching maximum when there are 0 to 10% of the unit testing methods,
and degrading afterwards.
2 one graph which was present in Dietrich and which I omitted is 'Average parameters', but first, there is no simple "best number of method parameters" (having all the methods with zero params means there is way too much is stored in the object itself, causing all kinds of trouble), and second, observed difference between 0.8 and 1.4 parameters per function is not significant for readability anyway
Conclusions
Amicus Plato, sed magis amica veritas.
Plato is my friend, but truth is a better friend
— attributed to Aristotle —
First, I have to say that I am well aware of all the hits I am going to take from hardcore fans of unit testing, including TDD fans. However, being hit hard for saying inconvenient truths is in my job description, so here goes my self-nomination for my cup of poison hemlock:
It is quite easy to get past the optimum amount of unit testing for your
project.3 And whenever your unit testing starts to affect your code in a
negative way - you should stop4
That being said:
- as with any other statistical analysis, there is no guarantee that correlation really means causation.
- this whole set of results is a relatively small sample, so things might still change:
- in particular, specific numbers are not to be relied on.
- OTOH, the results above are consistent with my own observations in million-LOC real-world projects.
- as it is observed above, some amount of unit testing is useful (which is also consistent with my own observations)
- It is just that unit testing is only one of the ways of automated testing - and shouldn't be seen as The Thing(tm) (or even worse - as The Only Thing(tm)) at least for statically-typed languages.
- Observations above are applicable only to statically-typed programming languages. Dynamically-typed languages are very different in this regard (and tend to require much more unit testing to be maintainable and refactoreable).
3 in fact, in Dietrich 40% of the projects went past this point
4 hey, heavy users of mocking frameworks!
References
[Dietrich] Erik Dietrich, "Unit Testing Doesn’t Affect Codebases the Way You Would Think"
[Dietrich.Cyclomatic] Erik Dietrich, "Understanding Cyclomatic Complexity"


Comments