














The following are slides and a script of my talk on CPPCON2017 in Bellevue, WA, US.

My apologies to those who’re not here yet, but we have LOTS of material (55 slides to be exact), so we don’t have time to wait.
Hello Almighty All. Today, I’ll be speaking about message-passing programs (in particular - (Re)Actors), and about eight different ways to handle non-blocking returns in them. In addition, I’ll try to make a very brief overview of existing proposals under the consideration by C++ committee (a.k.a. WG21) - and try to demonstrate how do they fit into our non-blocking returns.
That’s a lot of stuff, and to fit into allotted time, it has to be a very intensive session. My apologies if anything looks too sketchy; in the end I will try to provide a few pointers where further information can be found.

Before we can really start with the talk, I’d like to make an important announcement. I have to confess that it is not really MY presentation.
Rather - it is a talk by (da-dum)… this guy (and you can also see him on my t-shirt too).
It means that if there is anything good with this presentation - it should be attributed to me, and if there is anything bad - it is all HIS fault.
BTW, if you think that my accent is bad - you should be grateful that it is not him speaking; I can assure you that his accent is MUCH worse than mine (as you may guess, it is quite difficult to produce human sounds for a hare).

Preliminaries aside, we can proceed with the substance of this talk.
In part 0 of the talk (as we’re in C++ land, we HAVE to start everything from 0), I’ll try to define what is the task we’re going to solve.
First, we’ll have an extremely brief overview of the message-passing and (Re)Actors including their benefits, and then we’ll discuss non-blocking processing (which is VERY closely related to interactions between the main processing and return processing). In particular, we’ll mention that - depending on the whether we want to process intervening events while waiting for the result of outstanding operation - non-blocking processing CAN be simpler than blocking one.

There is no one single definition of message-passing, but to convey the idea, I think that it is the best to use the following adage which was provided in “Effective Go”:
Do not communicate by sharing memory; instead, share memory by communicating.
While this wording doesn’t come from C++-land - it does convey the concept (which is more-or-less equivalent to Shared-Nothing).
In practice, it means three things:
- first, all the processing within business logic is confined to one single thread (or at least “as if” it is single-threaded)
- second, there is no memory sharing (which in turn means that all the mutexes at the business-logic level are gone)
- last but not least, there should be a way to pass a message between different threads, processes, or even different computers

Unfortunately, we don’t have time to get into detailed discussion of the benefits of message passing, so I will just list them here, highlighting the most interesting ones.
Most importantly, message-passing allows to avoid cognitive overload (which arises whenever we’re trying to deal both with business logic and with thread sync at the same time). This, in turn, simplifies programming greatly.
Second, with message-passing, it is easy to make our programs deterministic, which in turn enables such goodies as testability and production post-mortem debugging (yes, this is used in practice).
And when it comes to concurrency, scalability, and performance - message-passing architectures tend to beat mutex-based ones too - in particular, due to zero contention and due to avoiding expensive context switches (and context switch can cost up to a million CPU cycles, if we account for cache invalidation); another performance-related consideration is that message-passing programs tend to have MUCH better spatial locality. Overall, from scalability point of view, message-passing systems are“Shared-Nothing” - and “Shared-Nothing” architectures rulezz forever.

There are many different ways to implement message-passing; however, to be specific, for this talk we’ll concentrate on one single incarnation of them - the one I prefer to name (Re)Actors.
(Re)Actors are historically known under different names - Actors, Reactors, Event-Driven Programs, and ad-hoc Finite State Machines. They’re widely used in very different environments (from GUI to HPC with game development in between), and are supported by different programming languages and frameworks (from Windows messages to Node.js); now it certainly looks as a good time for C++ to start supporting event-driven programming as a first-class citizen too.
Most important for us, however, is that while from now on we’ll be speaking only about (Re)Actors - most of our findings are generalisable to more generic message passing.
One exception is related to allocator-related serialisation - while it does work for (Re)Actors, at the moment I don’t know how to generalise it to all the message-passing programs.

As we’ll be speaking in terms of (Re)Actors quite a bit - let’s establish some basic terminology which we’ll use.
Let’s name a common denominator for all our (Re)Actors a Generic (Re)Actor. As we can see, GenericReactor is an almost-empty abstract class - with a pure virtual function react().
Let’s name “Infrastructure Code” a piece of code which calls Generic Reactor’s react(). Quite often - this call will be within so-called “event loop” as shown on the slide.
As we can see - there is one single thread, so there is no need for thread synchronisation within react(); this is very important for several reasons (including allowing for determinism and avoiding cognitive overload).
Let’s also note that get_event() function can obtain events from wherever-we-want-to - from select()/poll()/epoll()/kqueue() (which is quite typical for servers) to libraries such as libuv (which are common for clients).
Also, let’s note that event loop is not the only possible way to use (Re)Actors. In particular, it is perfectly possible to call (Re)Actor::react() from a thread residing in a thread pool, providing thread sync OUTSIDE of (Re)Actor (while scenarios where this is beneficial, are relatively rare, formally they’re perfectly valid). Most importantly, even in this scenario our (Re)Actor::react() stays completely thread-sync-free.
And finally, let’s name any specific derivative from class GenericReactor - a Specific Reactor. It is SpecificReactor which will actually implement our react() function with all the business logic within.
I need to note that a virtual-function-based implementation shown is not the only one possible; in particular, the same thing can be done using templates instead of virtualisation - without any differences for the our further discussion.

After we defined our landscape, let’s see what is the specific problem I’m trying to discuss today. It is a problem of non-blocking processing.
Non-blocking code has quite a bad reputation among the programmers; in particular, it is perceived to be significantly more complicated than equivalent blocking code.
As we’ll see, in part it can be attributed to the lack of adequate support for non-blocking processing in the programming languages, but in addition, there is some confusion about it.
In practice we need to distinguish two very different scenarios. The first scenario arises when we do NOT need to process any incoming events while waiting for the result of requested operation. In this case - if going non-blocking - we’re essentially using it ONLY to improve performance, and indeed, code complexity of non-blocking code INCREASES compared to blocking one.
The second scenario occurs when we DO need to process events while we’re waiting for the result of requested operation. Examples of such situations are numerous; as one all-important example, for an interactive program, refusing to process inputs while waiting for a result of outstanding over-the-Internet operation, results in effectively “hanged” programs, which is pretty much suicidal.
And if we’ll take a look at this second scenario from the point of view of code complexity, we’ll observe that while non-blocking code can be ugly, blocking code, to implement processing events while blocking, will need to resort to threads - and worse, thread sync, which, in turn, will make it MUCH more complicated than non-blocking one.
In particular, I am of a very strong opinion that combining of thread sync with business logic IN THE SAME PIECE OF CODE almost-inevitably leads to cognitive overload (exceeding the magic number of 7+-2 very quickly). This, in turn, means that reasoning about the blocking-code-which-processes-intervening-events inevitably becomes extremely difficult.

This dual nature of the complexity with relation to non-blocking processing leads us to the concept of “Mostly-Non-Blocking Processing”, where we’ll use non-blocking processing ONLY if there is a chance that we DO need to process events while we’re waiting for the result of our outstanding call.
On the other hand, under mostly non-blocking processing, we MAY block AS LONG AS we the outstanding operation is short enough, so we can postpone processing of the intervening events while waiting.
One such example includes accessing local disk or LOCAL database. For most of the real-world scenarios, we can say that if this takes too long - we should be already doing Fault Recovery rather than non-blocking processing.
Unfortunately, we don’t have time to elaborate on mostly-non-blocking processing; what’s most important for us now, is that (mostly-non-blocking or otherwise) we’re most interested in INTERACTIONS between main program control flow on the one hand, and processing of returned values on the other hand.
Let me repeat it once again: IT.IS.ALL.ABOUT.INTERACTIONS, nothing else.

Now, we can get to the real stuff. In Part 1 of the talk, first we’ll define The Holy Grail of the non-blocking processing. In general, we’d want our non-blocking processing to be as close to blocking one as possible, but there is a significant caveat related to those interactions mentioned a few seconds ago.
Then, we’ll proceed to taking a quick look at the eight ways of handling non-blocking returns, one by one. Of course, given our time restrictions, detailed analysis isn’t possible - but as promised before, I will provide pointers to a more detailed discussion at the end of the talk.
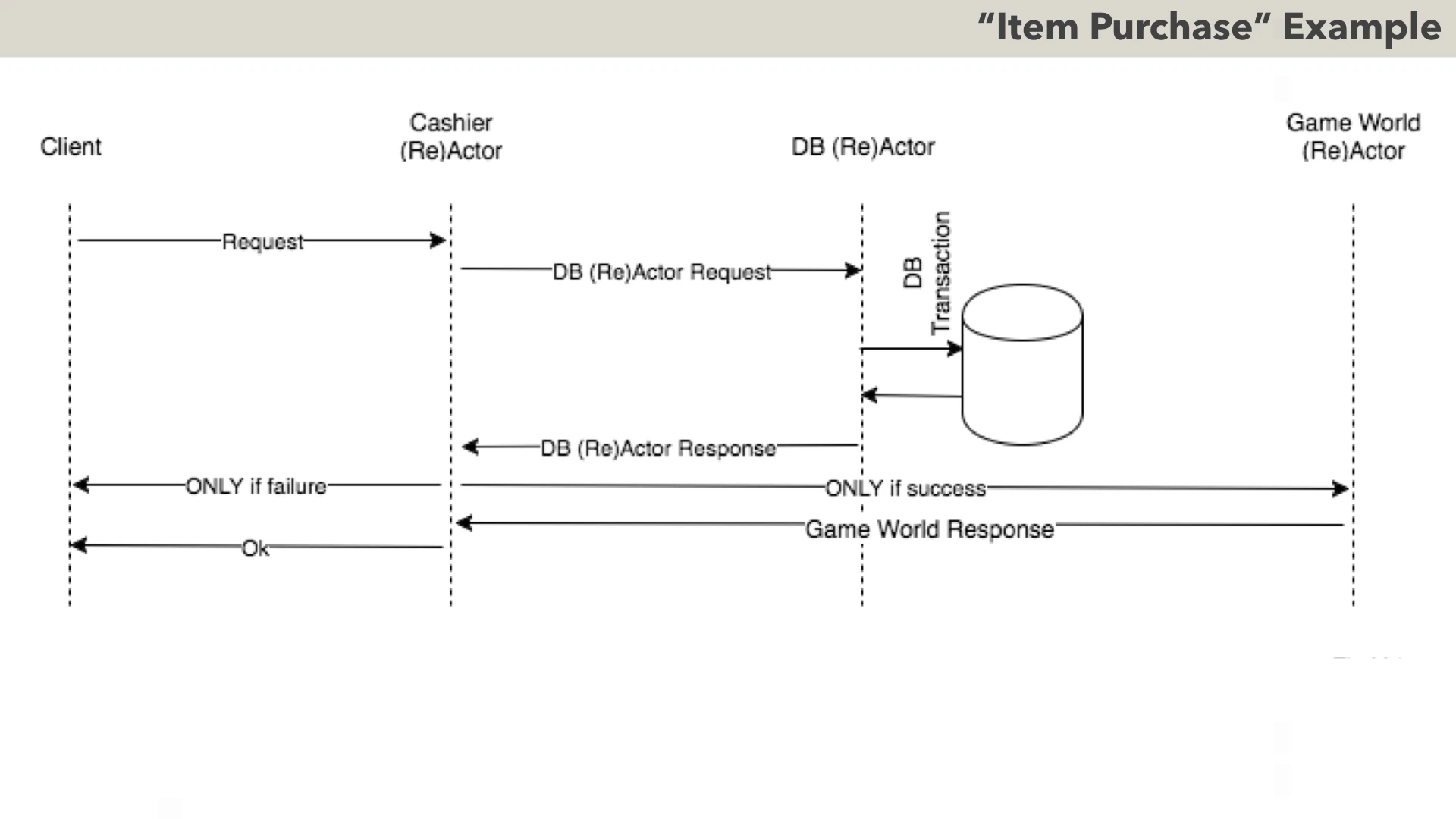
To compare different ways of handling non-blocking returns, we’ll take one simple close-to-real-world example - and will see how our 8 different approaches will handle it.
The idea of the processing which we’ll use as a litmus test for our different Takes, is shown on the diagram. We have a game, and a player who wants to purchase some item to be used in our game. Player tells Client what she wants to purchase - and then Client sends request to Cashier (Re)Actor, Cashier (Re)Actor issues a request to DB (Re)Actor, and receives reply. If the purchase has failed for whatever reason - Cashier reports the failure back to the Client. And if DB transaction was successful - Cashier (Re)Actor issues another request to the Game World (Re)Actor (so the player gets the item and can start using it), and notifies Client that the transaction went through ok.
By the standards of the distributed systems it qualifies as a VERY simple scenario - but as we’ll see a bit later, it is sufficient to demonstrate the differences between different approaches to handling non-blocking returns.

Let’s take a look at the blocking-code-which-implements-this-logic within Cashier (Re)Actor; while it is clear that non-blocking code cannot be as simple as the blocking one - we should aim our non-blocking code to be as close to this one as possible.
In our blocking version, everything looks very simple - there is a very modest amount of boilerplate code, and the essence of our interactions is very clear:
First, we’re making a blocking RPC call to our Database (Re)Actor,
and then, depending on the result of the first call - we may issue another blocking RPC call to our Game World (Re)Actor. That’s pretty much it.
Let’s also note that to have this kind of code - we have to assume that we do have some kind of Interface Definition Language (IDL) and an IDL compiler which generates stubs and skeletons for these blocking RPC functions (when the bright future described by Herb Sutter in his talk on Wednesday, materialises - we’ll be able to have in-language IDL, but at this time we’re not there yet).
We’ll also assume that our IDL compiler is sufficiently universal (or written by ourselves, which is not a rocket science) - and that it will generate everything-we-may-need not only for this blocking example, but also for ALL our non-blocking Takes.

When looking at our blocking code, we have to note that for non-blocking purposes, the blocking code we have seen is NOT ideal. In particular, as our non-blocking RPC calls are all about allowing interactions with our (Re)Actor while the call is outstanding, it means that the state of our (Re)Actor MAY change while we’re waiting for the results of the call.
As a result, the non-blocking code on the slide may occasionally fail.
Compared to the previous slide, all we did was just adding two highlighted lines - and while in blocking code they’re perfectly fine, in a non-blocking code the assertion may fail. Indeed, while we were waiting for the result of the dbPurchaseItem, there MAY have been an event which we need to process (after all - the whole point of non-blocking processing is to allow processing events while we’re waiting). And processing of this intervening event, while staying completely out of sight, MAY have modified the state of our CashierReactor.

To allow developers to know when such implicit-updates-to-state can happen - it is necessary at least to make it very clear WHERE EXACTLY such unexpected modifications can potentially occur.
On the slide, such points-where-state-can-be-implicitly-and-silently-modified, are marked with a “REENTRY” marker for function calls (there is no special meaning for REENTRY here, it is merely intended to illustrate SOME kind of marker). As we’ll see, equivalent markers can look VERY differently depending on the specific technology we’re using; however - my current point is that there should be SOME kind of indication to make the potential points where interleaving events can cause us trouble, VERY CLEAR to the developer.
With this in mind - I contend that the code shown, is the best one we can possibly get for a non-blocking code solving our task (at the very least, I have never seen anything better); as such - I consider it representing a “Holy Grail” non-blocking implementation for our example code. And - we’ll use this “Holy Grail” code as a baseline for comparison for all our 8 non-blocking Takes.

Historically, first non-blocking implementations were based on plain messages; such an implementation for our “Item Purchase” example is shown on the slide. Yes, it is THIS bad.
Let’s take a bit closer look at it:

First, we need to create a struct to store the context of our request (so we can handle return properly). There is nothing really meaningful here - but we still have to write this boilerplate code.

Then, we have to add a map of request_ids to this request data, so we can find the necessary request context when reply arrives back.
While in some cases it is possible to say that there is only one outstanding request per type, in general - it is better to avoid such things as they have a tendency to become unmanageable rather quickly. The same stands for ad-hoc tricks which allow to identify replies by embedding additional information into reply instead of request_id.

As we got our initial request from the Client - we need to save the context into our struct, compose the message using the function prepared by our IDL compiler, send the message, and save our struct into the map.
BTW, in addition to being verbose, this code is also error-prone: this kind of code is not only cumbersome, but is also pretty easy to get wrong.


Then, on receiving reply from DB (Re)Actor, we need to find the request in the map, and check its status
Now, just for a change, we have one line of non-boilerplate meaningful code (the one which was present in our blocking version)


...but as you have already guessed - it is followed by even more boilerplate.
Overall, amount of boilerplate code in Take 1 is enormous: out of over-70(!) lines-of-code in Take 1, only about 10 are meaningful. This becomes especially obvious when placing Take 1 and our “Holy Grail” baseline code side by side…
This slide pretty much summarises the problems with Take 1: amount of boilerplate code is soooo large, that all the business logic is completely buried in it. What’s interesting though - is that I’ve seen perfectly working systems based on this kind of non-blocking handling (though their maintenance costs was a completely different story).

For our Take 2, we’ll consider a technique which is quite popular in game development today - and based on non-blocking VOID-ONLY RPC calls. The idea behind using void (and non-throwing) RPC calls is that as there is no reply whatsoever to such calls - there is no question “what to do when the reply arrives”.
On the other hand - such void-only RPC calls provide only very marginal improvement over plain messages; in particular, to implement a typical request-response exchange, we need to have two void RPC calls - one to send request, and another to send reply back.

As a result, most of the boilerplate stuff from Take 1 such as request context struct,

map of request_ids into these structs,

as well as filling context on sending request, and finding it on receiving reply - are all still here, with all the associated error-prone stuff.

Overall, improvements in readability and reduction of boilerplate code, provided by Take 2, are not that large as we’d like them to be. While 50 lines-of-code is indeed better than 70, it is still five-times more than in our target “Holy Grail” code.

Our Take 3 is about object-oriented callbacks. It is a thing which I was doing myself almost 20 years ago when architecting a pretty large (Re)Actor-based system; the architecture is still in use pretty much without changes - and it does work.

As we can see from slightly increased font size, Take 3 is just a bit less verbose than Take 2. With Take 3, it is all about callback objects - and it takes lots of boilerplate to describe them. We need a callback object to handle return from our non-blocking request to the database...

and another callback object for the non-blocking call to our Game World

And only after we’re done with this meaningless boilerplate (and are over 50% down our Take 3 code) - we get to somewhat-meaningful stuff (it still has lots of boilerplate, but at least it is interspersed with SOMETHING meaningful).
Currently highlighted is the code processing original purchase request from Client...

and here is return handler. One thing which we can see, is that - compared to Takes 1 and 2 - there is no explicit handling of the request_id-to-callback-data maps; in Take 3, while these maps are still present behind the scenes (there is no magic here), we managed to hide them from the view of app-level developer (which is a REALLY BIG relief).

If we compare our Take 3 to our baseline “Holy Grail” code, we’ll see that Take 3, while being less verbose than Take 2, still has like 4-times more lines of code than we’d like to have. On the plus side, however (in addition to being less-error-prone than Takes 1 and 2), we can see that meaningful code in Take 3 is concentrated within a smaller number of lines, which significantly improves its readability.
Overall, Take 3, while being verbose, has been observed to be perfectly usable and perfectly working. I would even go as far as saying that it is the best thing we could do before the advent of C++11, and most importantly - before lambdas.
Up to now, all our Takes were doable even in C++98; now let’s see how we can improve it with the power provided by C++11.
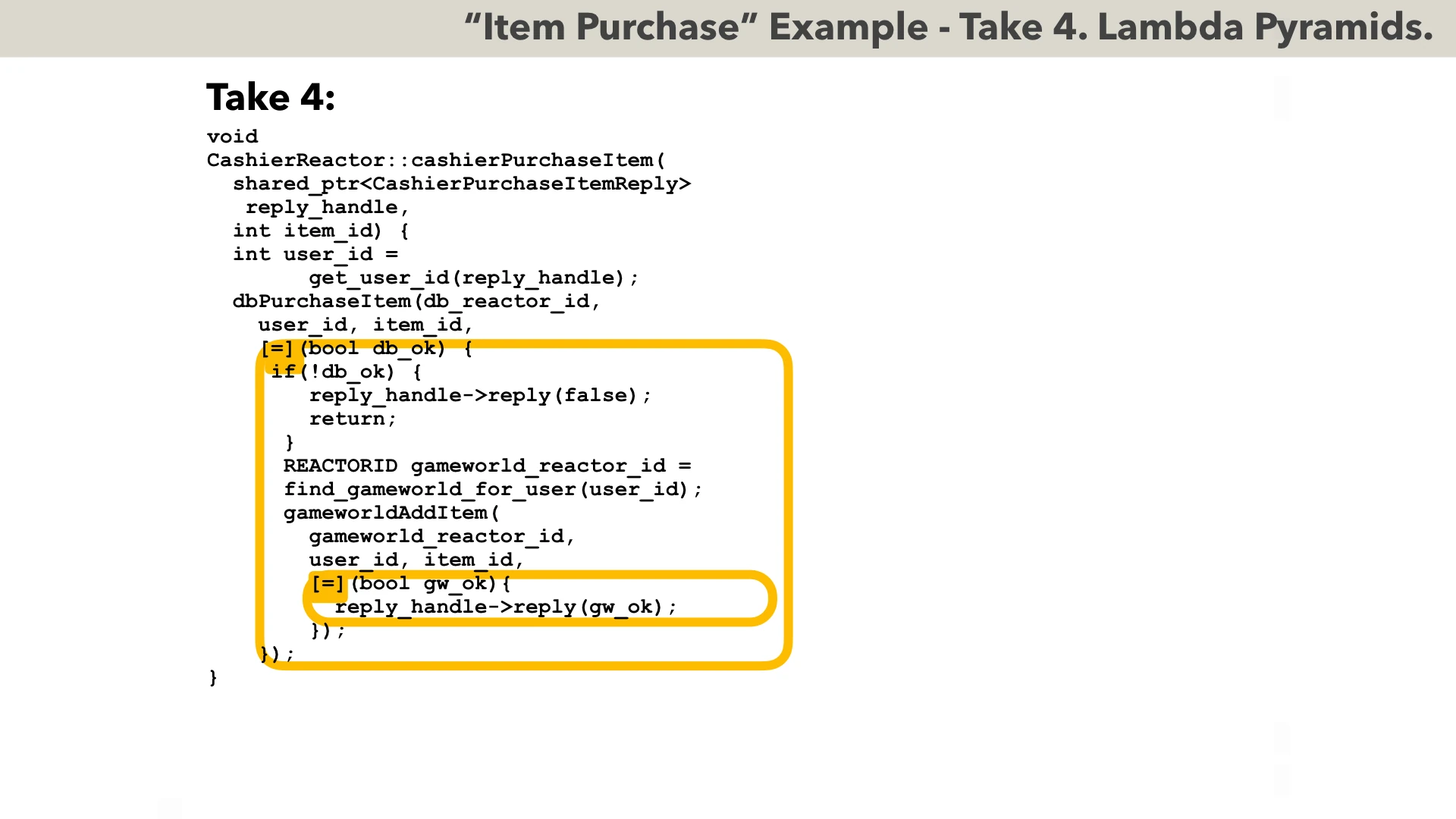
Our Take 4 is all about lambdas, and more lambdas, leading us to the infamous “lambda pyramid”. We can immediately see that the amount of boilerplate code went down very significantly; actually, it is the first time when our non-blocking code became somewhat-readable on a single slide.
Ideologically, the code in Take 4 is actually very similar to the Object-Oriented Callbacks from Take 3: it is just that instead of those verbose manually-written object-oriented callbacks, compiler creates equivalent lambda closures for us behind the scenes.
One important point about C++ and lambdas is that while we’re using lambda capture ”by copy”, it still captures current object (the one referred to by THIS) by reference. Accidentally, this is EXACTLY the behaviour we want for our purposes: we DO want to capture stack variables by value (so they survive return from our cashierPurchaseItem function), but at the same time we DO want to capture our (Re)Actor object by reference, so we can access its CURRENT state while processing non-blocking returns.
If we compare our Take 4 to our “Holy Grail” code, we’ll see that verbosity-wise they’re about the same.

However, readability-wise Take 4 is still far from perfect (and it will become more obvious if we introduce exception handling). Most importantly, the code which is logically linear on the right side - becomes NESTED within our Take 4 code. This (as well as rather counterintuitive indents for what-is-essentially-linear-logical-code) is what earned Take 4 approach the name “lambda pyramid”; as soon as the number of non-blocking operations in original non-linear code goes to 4-5, the whole thing becomes rather poorly readable.

Let’s see how we can improve it further. Our Take 5 is about so-called FUTURES.
Very very briefly, the idea is to create a placeholder, known as “future”, where the result of some operation which-will-only-become-known-in-the-future can be stored

And as soon as we have these “future” objects - we can specify actions which have to be done as soon as the result within the future becomes available. These actions are often referred to as continuations.

If we compare our Take 5 to our baseline “Holy Grail” code - we’ll see that verbosity of futures is still in check, but, unlike “lambda pyramids”, the code-which-was-linear-in-blocking - is still linear with futures.
I’d certainly say that Take 5 is the best we have so far. BTW, as an added benefit, concepts such as “we need to wait for TWO non-blocking RPCs to complete”, are easily expressible with the futures too.

Last but not least about our Take 5, let’s note that in spite of being CONCEPTUALLY similar to std::future<> in some sense, our ReactorFutures are not identical to it. Most importantly - std::future<> is primarily about THREAD sync, and our ReactorFutures, being used within one single thread, are quite different, and are more similar to Facebook’s folly::Futures (though it SEEMS that future futures from std::experimental will implement continuations, and will become what-we-want).

If we extend the idea of futures a bit further, we can get to constructing the whole code trees from lambdas. The value of such approach becomes obvious as soon as we realise that not all the code is linear, and that there are conditions and exceptions. As we’re very limited on time today, I won’t give an example with conditions - but here is an example comparing our-“Holy Grail” code with exceptions added, to the “Code Builder” approach in our Take 6.
The idea behind “Code Builder” is that we’re effectively “building” the code tree in runtime (in CCode object), and as soon as the code tree is built - we can run it in a perfectly asynchronous manner. Most importantly for our current purposes is that elements of our code tree directly correspond to the elements of our original “Holy Grail” code:
Whenever we have “try” on the right side - we have “ttry” on the left, whenever we have linear code on the right - we have more-or-less similar code on the left too, and so on. And even if we’d have loops with non-blocking calls within - we’d still have exact 1-to-1 correspondence between blocking code and non-blocking one, and WITH EXACTLY THE SAME NESTING TOO.
Overall, Take 6, while being admittedly more verbose than Take 5, is MUCH more flexible than that, and (before the advent of co_await) could be a good choice for more complicated use cases.

BTW, if we introduce preprocessor to the picture, we can make the code in Take 6 significantly less verbose (while preserving all its good properties). Whether improved readability is worth the trouble of debugging code which uses heavy preprocessor macros - is still unclear, but such a possibility does exist.

Our Take 7 will be about stackful coroutines and/or fibers. Fortunately for us, we don’t have to go into a lengthy discussion about the differences between the two; for us, it is sufficient to say that fibers and stackful coroutines are pretty much the same for our purposes.
In not-exactly-standard but still-widely-cross-platform C++, stackful coroutines are represented by boost::coroutines (though personally I’d prefer my IDL compiler to use boost::context directly).
As we can see, the code in our Take 7 on the first glance looks better than that of the Take 6 and Take 6a. However, it comes at a cost of two important caveats...

First, with stackful fibers/coroutines, it becomes very difficult to serialise state of our Reactor - and to achieve quite a few all-important properties of Reactor (including post-mortem debugging and low-latency fault tolerance) it IS necessary to serialise Reactor state.
Granted, in C++ serialisation is not a picnic even with lambdas, but with stackful co-routines I don’t even know how we can approach this task (BTW, if you do - I would be VERY interested in hearing it after the talk).

Even more importantly, stackful co-routines come with a Big Fat word of caution. While with fibers/coroutines we CAN avoid futures and write the code EXACTLY as a blocking one - we DON’T really want to do it.
When we compare Take 7x (using ‘x’ to denote that it SHOULD NOT be used) to the “Holy Grail” code - we’ll notice that there is one thing missing from the Take 7x: it is those “REENTRY” markers which are necessary to indicate those points where the Reactor state can be modified. This, in turn, as we discussed above, leads to difficult-to-see errors, and to significantly increased code maintenance costs. As a result - I do NOT recommend using Take 7x in real-world projects.

A really short real-world story in this regard. Some time ago, I was presenting the Take 7x option to a billion-dollar company having several million-lines-of mostly-non-blocking (Re)Actor code (the idea was to replace Take-3-they’re-currently-using, with something more palatable). Long story short: right away after seeing this Take 7x - they asked me: “Hey, how we’ll know those points where the state can be modified??“.
It illustrates one of the earlier raised points - that THOSE REENTRY MARKERS are REALLY important for real-world non-blocking development.

Our last Take, Take 8 is related to the concept which is well-known for the other programming languages (such as C#), but is a new-kid-on-the-block for C++. I’m speaking about await (which was renamed into co_await in recent versions by WG21).
As of now - it is NOT a part of standard yet, and changes are still to be expected; on the other hand - implementations are available both for MSVC and Clang.
As we can see, the code in Take 8 is almost-exactly the same as our “Holy Grail” code on the right.
Even our REENTRY markers have their direct counterparts in Take 8.

Still, we have to note that at least as of current C++ proposals, Take 8 is not 100% ideal for our purposes. Most importantly, it has problems with serialising the state of our (Re)Actor, and while the problem is NOT as severe as that of Take 7, it is still going to cause quite a bit of trouble. On the plus side, it MIGHT be possible to serialise Take 8’s state as a part of serialising the whole allocator - but it is rather tricky, relies on certain properties of underlying OS, and as a result - causes complications with ASLR. From our current perspective- it is currently not 100% clear whether it is really GUARANTEED that ALL the co_await frames will REALLY go via a user-definable allocator in ALL the compilers and libraries (also we need a guarantee that await-frames won’t use anything else but allocator, so any on-stack storage for await frames doesn’t happen).
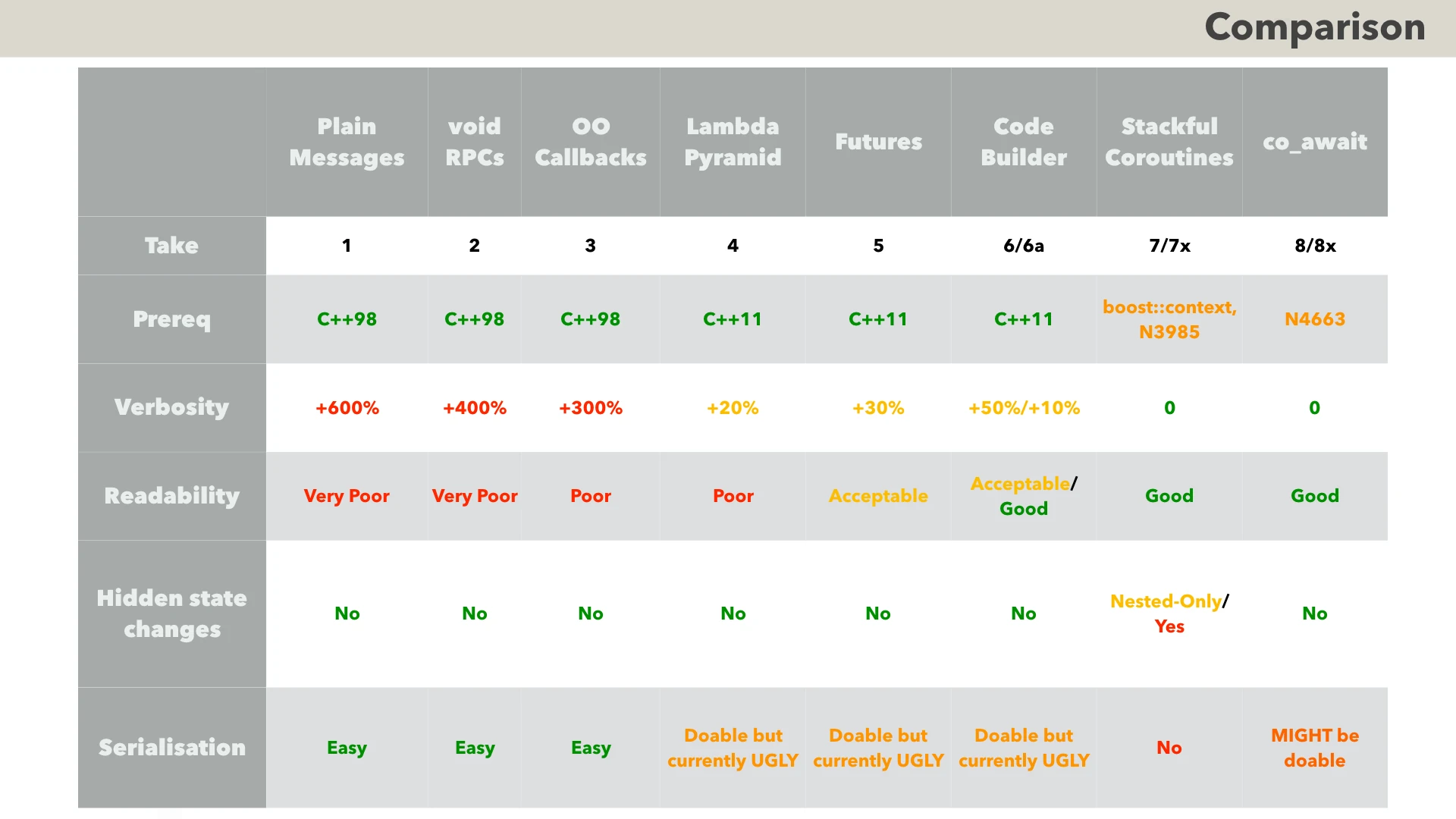
Now, as we’re done with describing our Takes - let’s compare them. Most of this table should be self-explanatory, but a few things do need an additional word or two:
- Of course, readability is inherently subjective, but it certainly exists - and it is certainly very important.
- As for “Hidden State Changes” - it is essentially about having that REENTRY marker (or a reasonable facsimile) to denote points where state of the (Re)Actor can be implicitly changed.
- Note that for Take 7 - we cannot really enforce REENTRY markers on the functions-which-call-our-RPC-functions. This is pretty bad, as we’ll need to resort to non-enforceable things such as naming conventions to indicate such functions-which-can-cause-sudden-state-change; this, in turn, will require to spend time looking for any violations of such policies, which, while not fatal, certainly won’t make our life easier.
- With regards to serialisation of Takes 4 to 6 - it hinges on serialising lambda closures; while as of now, I don’t know of a way to serialise lambdas as such - it IS possible to do one of two things:
a) write a kinda-preprocessor which automagically replaces lambdas with equivalent OO callbacks during build stage.
or b) intercept ALL the allocations including lambda allocations, with a custom allocator - and to serialise the whole allocator-including-both-our-own-stuff and lambdas together. As noted above - this is quite risky, and depends on OS-related stuff, but I know at least of one working implementation of it.
While neither of these approaches is perfect - they seem to work, though with a fair share of trouble.
- For co_await - my current understanding is that we have only the second option (serializing allocator as a whole, including all the co_await frames), and it is a rather risky one (there are both risks related to clashes of virtual addresses when deserializing, and risks related to compilers/libraries bypassing our user-defined allocator for whatever-reason).
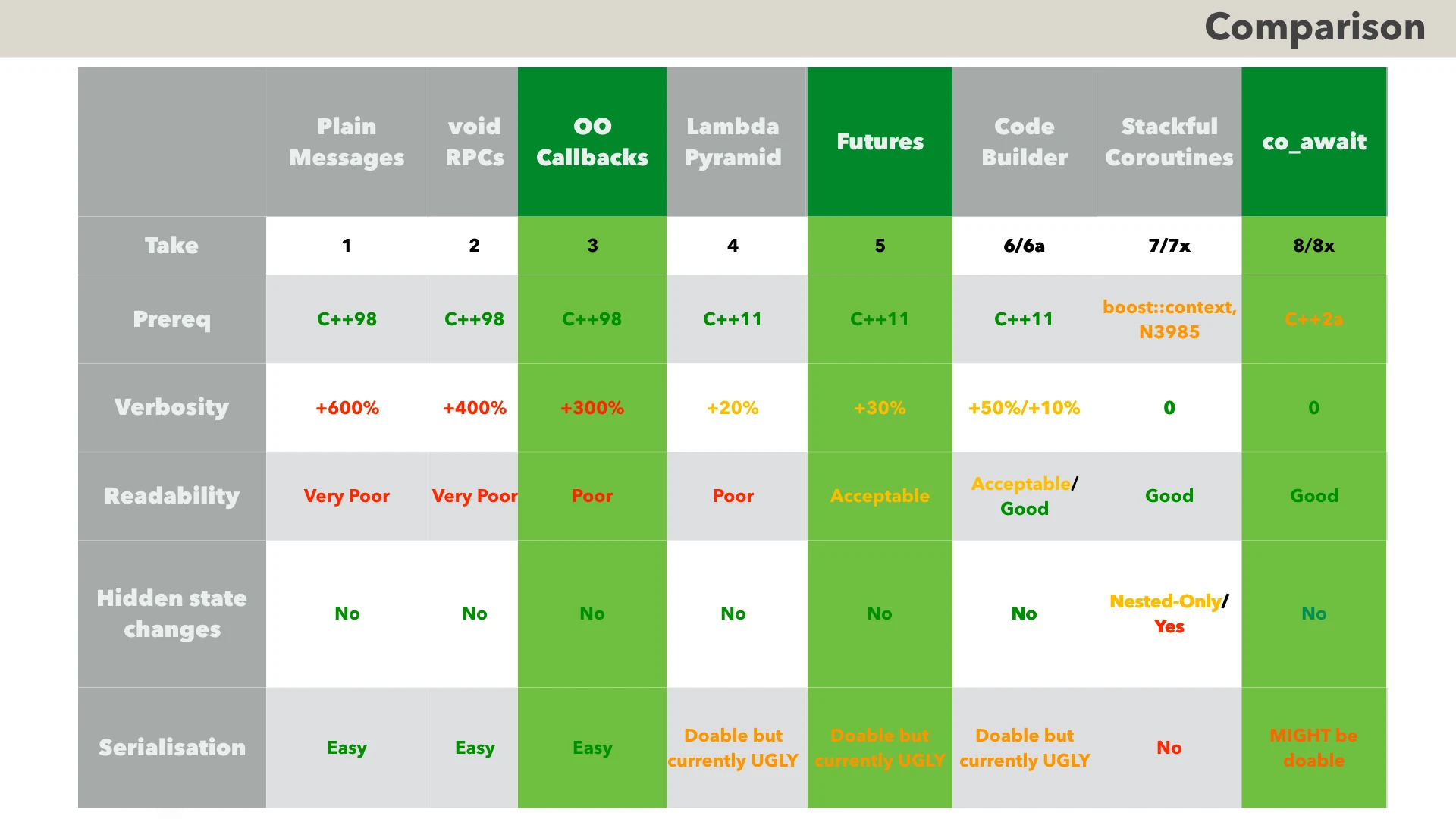
Overall - I’d say that depending on specifics of your project, THREE different approaches may happen to be viable:
- OO callbacks are good, old, working-for-sure even in C++98, and having no problems with serialisation. They are not exactly the most readable ones - but if you want a sure-fire approach which will serialise your state without any need to experiment - it will work at least for smaller projects pretty well (and I’ve seen it working for a million-lines-of-code project too).
- futures are good if you want to stick to C++11. On the other hand, serialisation is going to be a headache - but is generally solvable one way or another.
- co-await is almost-perfect for our purposes. Still - serialisation is going to be even-a-bigger-headache than for futures (while hopefully will be still doable).
To summarise - while quite a few of our Takes are usable in real-world, unfortunately, NONE of them represents an ideal solution for our non-blocking problems (at least not yet).

Now, let’s discuss current C++ standard proposals, and what we want from them from our non-blocking-handling perspective. Relevant C++ proposals in this regard include:
- co_await, currently billed as “stackless coroutines” (formerly Resumable Functions). As of now, co_await seems to be the most likely thing to make it into the C++2a, and IMNSHO is certainly the most viable proposal out there. There is still a significant issue which current co_await, related to difficulties with serialisation (while it seems to be possible at allocator level, it is rather risky and cumbersome).
- boost::-style stackful coroutines (though I know that Gor prefers to call them fibers). From our perspective - with stackful coroutines, one big problem is that we can hide REENTRY markers (which is pretty bad for our purposes, as to prevent sudden state changes causing us trouble, we’ll need to resort to the stuff such as naming conventions <ouch! />). PLUS - situation with serialising stackful coroutines is even worse then for “stackless” ones (rough translation: “I have no idea how to serialize stackful coroutines even if we’re speaking about deserialising within EXACTLY the same executable”).
- The next proposal on our list is so-called Resumable Expressions. To be perfectly honest, I do NOT like this proposal for two Big Reasons: first, it doesn’t allow to enforce markers equivalent to REENTRY, and second - when implementing await-like logic, they’re using mutexes (and with devastating results too); more on it a bit later.
- The last one on our list is so-called Call/CC (call with current continuation). I have to admit that I don’t know much about Call/CC (that’s why the grey color on the slide), but it seems to me that it is way too low-level to be intuitively used in app-level code.

Now, let’s give a few pointers on what-is-important-for-our-non-blocking-handling-purposes implementation-wise. As none of these newer proposals are carved in stone yet (and implementations are even less so) - there are a few things out there which either do-exist-but-can-magically-disappear, or things which we’d like to add (at least in the long run).
- First, we DO need to see those points where the state of our non-blocking program can suddenly change. In this regard, I am a big fan of so-called Suspend-Up-and-Out model used by co_await nee Resumable Functions. Using an opportunity to speak to the members of the almighty committee - please PLEASE do NOT throw Suspend-Up-And-Out model away, especially on the premises such as those in P0114R0.
- During our discussion, we mentioned serialisation quite a few times; overall - it is a VERY important feature in the context of using deterministic properties of the (Re)Actors (and message-passing programs in general); in particular - practical implementations of features such as post-mortem debugging and low-latency fault-tolerance require serialisation (more specifically - “Same-Executable Serialization”).
On the other hand, it is clear that currently - without ANY built-in serialisation in C++ - we cannot ask to implement serialisation for lambdas and co_await frames. Still, there are TWO things we can (and I think SHOULD) ask for:
(a) we have to be sure that await-frames are using ONLY heap (and no stack, nothing else), and (b) we need an ability to control allocator which is used to store lambda closures and await frames. This will allow us to implement serialization which we need; it will be ugly, but as a stop-gap measure, it will do.
In addition - WHEN serialisation is supported (using static reflection or otherwise) - we want to have it supported also for lambda closures and for await-frames, please make sure to keep us in mind <smile />. In particular - when static reflection is ready, please make sure it DOES cover BOTH lambda closures AND await-frames.
Last but not least, for stackful coroutines - having current stack serialised (and deserialised later - assuming it is EXACTLY the same code deserializing) - might help too.
- Last but certainly not least - we DON’T want mutexes within implementations of whatever-coroutines-are-pushed-at-us by the almighty committee. As practice has shown - mutexes are soooo difficult to deal with, that even the committee members can easily leave a bad mutex-related bug in their code.

Let’s take a look at the proposed implementation of await in P0114R0 (a.k.a. Resumable Expressions). As for using it - it is more or less on par with Take 7 (not perfect, but more or less usable); however, the devil, as always, is in details.
I would be REALLY happy to say that simulation of await() in P0114R0 qualifies as an implementation detail, so we shouldn’t care about it, but - there is a significant problem with this specific implementation.
The problem is that emulation of await in Resumable Expressions is mutex-based. In practice, it will mean a potential extra thread context switch per await, and with the cost of the context switch ranging from 2000 CPU cycles to - if we account for cache invalidation costs - to a MILLION CPU cycles, I don’t really like it.

To make things even worse, implementation proposed in P0114R0 calls a user-defined function from under a hidden mutex. Such a practice has been observed to lead to unexplainable-to-user fatal deadlocks happening-once-a-month. It is worth noting that this problem was first demonstrated as early as in 98, when analysing a hopelessly-buggy multithreaded-STL implementation (carrying a copyright by another member of WG21). The worst case of observed behaviour was what-is-seen-in-developer-space as a “deadlock on one single recursive mutex(which is a thing which cannot possibly happen - unless there is a hidden mutex conveniently provided by the library exactly to allow this kind of deadlock to happen). My educated guess is that the same problem exists for P0114R0.
Necessary disclaimers:
- Code in P0114R0 is convoluted enough, so there is a chance that I’m misreading it
- More importantly, both these problems arising from using the mutex MIGHT be fixable (or MIGHT be not). TBH, I don’t even see why this mutex is necessary in the first place - but IF there was a reason, we MAY end up in trouble.
Fortunately, our further discussion does NOT depend on the result of the P0114R0 implementation of await being fixable. Still, it DOES illustrate an important point of avoiding mutexes when implementing coroutines.

To summarise this hour-long talk in one single slide:
- First, we DO need to handle non-blocking returns.
Moreover, the whole point of handling non-blocking returns is to allow interaction of intervening input events with the state WHILE non-blocking call is in progress
As a result - we DO need a way to clearly see whenever the state has a potential to change.
- Second. Unfortunately, none of the options we have to handle non-blocking returns in C++ is perfect. Some of the options are outright ugly, some don’t allow to see potential-for-state-change, and some are not easily serialisable.
- Still, I am sure that with co_await, it is about as-good-as-it-can-realistically-get in foreseeable future.
On the other hand, when serialisation comes to the standard, I’d certainly appreciate a way to serialise (or statically reflect) such things as lambdas and await-frames.

This concludes our very intensive talk; I hope that I was able to convey my thoughts in a digestible manner. Now, we have 3 minutes to answer some of your questions.
References:
- ‘No Bugs’ Hare, “Development&Deployment of Multiplayer Online Games”, Vol. II, pp. 70-129.
- Kevlin Henney, “Thinking Outside the Synchronisation Quadrant”, ACCU2017- “Effective Go”, https://golang.org/doc/effective_go.html
- Dmitry Ligoum, Sergey Ignatchenko. Autom.cpp. https://github.com/O-Log-N/Autom.cpp
- N4463, N3985, P0114R0, P0534R0
- Chuanpeng Li, Chen Ding, Kai Shen, “Quantifying The Cost of Context Switch”, Proceedings of the 2007 workshop on Experimental computer science
- “STL Implementations and Thread Safety”, Sergey Ignatchenko, ”C++ Report" , July/August 1998, Volume 10, Number 7.


Comments