














The following are slides and a transcript of my talk on ACCU2017 conference in Bristol, UK.

Good afternoon everybody. Thanks for coming, and I hope that during this talk I will be able to tell a thing or three which might be of interest.
As it is said on the tin, I am determined to speak about Determinism (pun intended).
I have to apologise in advance for the number of slides, text, and bullet points - but the topic is quite complicated, and we WILL need most of that stuff.

The first part of the talk will be about ME trying to convince YOU that determinism is a good thing to have - AND that it is worth the trouble of implementing it.
As you can see - there are quite a few items on the list of topics for part I, and we’ll discuss each of them in due course. For now, however, I want to emphasise the most interesting ones, such as Same-Executable Determinism vs Cross-Platform one, Replay-Based Regression Testing, and production post-factum (and even post-mortem) debugging (with a video by an AAA game company showing how they used this technique for one of their games).

In the second part of the talk - we’ll proceed with discussing HOW TO IMPLEMENT those deterministic components which have so many useful properties.
As you can see - it is an even longer list, and once again, for the time being I will merely highlight the most interesting points. These include dealing with multithreading which is a bad source of non-determinism, a technique which I tend to name “call wrapping” (which allows to isolate determinism coming from any conceivable system call), Compatibility Issues, which tend to plague the deterministic implementations - but fortunately only when we’re going beyond Same-Executable Determinism (which is fairly rare), and some of non-issues - which may LOOK as a threat to determinism on the first glance, but which are not.

By this time - we’ll cover those topics related to making of - and benefiting from - deterministic COMPONENTS. In the third and last part of this presentation - we will briefly discuss issues which are related to building the whole large DISTRIBUTED SYSTEMS from these COMPONENTS. Let’s note, however, that building distributed systems is a very large topic - which also depends on the specifics of the applications involved - and we will be able to provide only a very cursory overview of it.

Before we can really start with the presentation, I’d like to make two important announcements. First of all, I have to confess that it is not really MY presentation.
Rather - it is a presentation by this guy (and you can also see him on my t-shirt too).
It means that if there is anything good with this presentation - it should be attributed to me, and if there is anything bad - it is all HIS fault.
BTW, if you think that my accent is bad - you should be grateful that it is not him speaking; his accent is MUCH worse than mine.
And the second and the last thing I want to mention before we can start: slides for this presentation are available online at ithare.com, so if you have your WiFi working and need to take a second look at a slide which is already gone - you can find it there.

Preliminaries aside, we can proceed with the substance of this talk.
The first part of the talk is all about different definitions of determinism, and benefits which can extract out of it.

First of all, let’s start with defining determinism. Our very first definition will go along the following lines: "A program is deterministic if and only if its outputs are 100% defined by its inputs”.
This definition is quite obvious, and while (as we’ll see later) it leaves quite a bit of room for further interpretation - it will do for the time being.

There are several important observation which follows from our Definition 1. The first one is that "Non-deterministic program cannot be fully testable using only deterministic testing"
This observation is quite obvious (ok, formally it will take half a page to write the proof down - but within this presentation we don’t have enough time to spend it on formalities).
The second observation is that "“Non-deterministic tests have two problems, firstly they are useless, secondly they are a virulent infection that can completely ruin your entire test suite.” This observation, made by Martin Fowler back in 2011, is not easily formalisable - but very briefly, the reasoning behind goes along the lines of “non-deterministic tests won’t be trusted, and will get ignored”. As a side note - sure, there are special methods for testing RNGs (starting from good ol’ Marsaglia Die-Hard testing suite) — but that’s pretty much all usable non-deterministic testing we’ve got (and whoever has run the Marsaglia test - knows how difficult it is to interpret test results, which further supports arguments pushed forward by Fowler).
Now, from these two observations, we can deduce the following observation 3: "Non-deterministic programs are not fully testable". Let’s note that this observation is not entirely strict, and that it is possible to construct use cases when it doesn’t work (RNG testing is one such example), but it certainly stands for the vast majority of real-world applications.

To illustrate the importance and power of our Observation 3, let’s consider the following two trivial examples. A side note: while code snippets in this presentation are using C/C++ - they’re not really language-specific, and exactly the same concepts will apply across the board.
The first of our examples will be a deterministic function f1(). Test harness for such a function will be fairly straightforward - we’ll just need to intercept stdout, then call the function with required parameters - and bingo! - we have our test - and can run it as a part of our build process to make sure there are no regressions.
But let’s imagine that a bit later, we decided to IMPROVE our function f1(), and produced another function f2(), adding a printout of current time. The whole function became non-deterministic - and this also greatly complicated our job as testers. Not only we need to provide many more test cases - but also RUNNING THOSE TESTS AND ANALYSING RESULTS IS GOING TO BE MUCH MORE COMPLICATED. Sure, our test harness can get or set current time before running f2() - but we don’t have any guarantee that the time will stay the same until the call to time() is reached. As a result - we’d need to account for potential discrepancies - and probably to re-run the test several times to make sure that discrepancy percentage is within the expected boundaries. And for a non-deterministic program which is more complicated than f2() function - this task will become insurmountable very quickly.
On the other hand - of course, we can just parse out current time from our output and make our testing deterministic and well-defined once again - but it will mean that we’re consciously making certain aspects of our function f2() essentially untestable.

From a bit more practical point of view, let’s note that for our program to be deterministic, it is sufficient that (a) we can record all its inputs; (b) when replaying these recorded inputs against the same program, we always get the same outputs.
This interpretation of determinism is of a very significant practical importance; in fact - most of the benefits we can get from determinism, are based on this record-replay paradigm.
As a result - from this point on, we will assume that we do have a way to record all the program inputs - and to replay them later. How to do it - is a different story, which we’ll discuss a bit further down the road.

Going a bit further into definitions - let’s define two different (and again - very practically important) subtypes of practical deterministic programs:
Definition 2a. "Program is “same-executable- deterministic” if replay guarantees to produce the same result only when it is run on exactly the same executable as the one where recording was made"Definition 2b. Program is “cross-platform-deterministic” if replay guarantees to produce the same result on ANY platform as long as source code is the same"
As we can see, the difference is all about the relations between the recording program - and the replaying one. In definition 2a of “same-executable determinism”, it MUST be the same executable (that is, not only coming from the same source code - but also produced by the same compiler with the same compiler options for the same target platform). In definition 2b of “cross-platform determinism”, it should be still the same source code, but compiler, compiler options, and even platform can be different.
As we’ll see later, in practice “same-executable determinism” is sufficient to get most of the deterministic goodies; on the other hand - “cross-platform determinism” for real-world programs is known to be VERY ELUSIVE (in particular, due to floating point issues).
And, as we’ll also see later, there are some in-between variations too.

Now, as we defined what determinism is about - we can proceed to discussing its benefits.
The most obvious benefit of determinism, is 100% reproducibility of your bugs. And for anywhere decent developer team, 100% reproducible bug becomes a dead bug very quickly. I worked for quite a few teams where 95% reproducible bugs of reproducible bugs were fixed within a few hours.
From my experience, if going beyond 3rd-party bugs, the most elusive bugs were ones in multithreading - and exactly due to problems with reproducing them. If a bug happens only once a month on a customer’s server - it isn’t likely to be fixed overnight. Once upon a time, we even went as far as writing our own fiber-based thread simulator - exactly to make the system deterministic, and to make bugs reproducible. And as soon as simulator was in place - debugging has sped up at least by factor of 10.
While we’re at it - let’s note that to have 100% reproducibility of the bugs - it is sufficient to have “same-executable determinism”.

Our next determinism-related improvement in testability is Replay-Based Regression Testing. The idea behind it is simple - if we have version N and have records of the inputs and outputs of the real system on version N - we can run them over version N+1, and see whether there are any discrepancies.
One problem behind such Replay-Based Regression Testing is that for it to work, we need that version N+1 should have EXACTLY the same functionality as version N has had (otherwise we’ll be spending time on figuring out whether the discrepancy is legitimate or not, and all subsequent replay after very first legitimate discrepancy will be impossible). And - well, for most of the development out there it is not realistic.
This, however, can be mitigated by the following approach:
- first, we split all changes intended for version N+1 into 2 categories:
- those changes not supposed to modify existing logic (this will include most of new functionality)
- those changes modifying existing logic
One way to implement this split is to attribute all the commits to issues (you’re already doing it in your project, aren’t you?) - and attributing issues to either category is usually pretty easy, which gives us a pretty good idea of whether a specific commit is expected to modify logic.
In practice, most of the time it will turn out that most of added new features (which usually take majority of development) will fall into this category. Most of the time - new features will require some effort from end-user to be activated - and without this new input, the feature should silently sit there, doing exactly nothing.
Then, we can make version N½ consisting only of version N + non-modifying changes, and replay-test it using records from version N. As version N½ is not supposed to have any observable differences from version N - it should produce exactly the same results as version N.
While this half-hearted approach to regression testing cannot test ALL the changes, even regression-testing HALF of the changes (and from what I’ve seen, it usually was more than half) - is a significant improvement compared to regression-testing NONE of the changes.
Let's note that to enable replay-based regression testing, we need a bit more than same-executable determinism, but less than full-scale cross-platform determinism; in my Overload article on the topic, I named it “Same-platform determinism against minor changes”. In practice - it can cause some issues, but these issues are inherently solvable during testing (and without costing arm and leg either).

Two further fields where determinism comes handy, are equivalence testing and fuzz testing.
Equivalence testing arises when we need to do one of the following:
- test new implementation of the same thing, or
- separate code bases, or
- test equivalence under different platforms/compilers.
In practice - equivalence testing can (and should) use records from production - and tends to work very well in these scenarios. Moreover, the first option - testing new implementation - is the only way I know to replace badly-obsoleted-code which nobody-dares-to-touch. Even when new equivalent version is written - convincing management to replace an old working-but-unmaintainable one is usually impossible without a very serious equivalence testing.
As for fuzz testing - it is routinely used for finding security holes in the code; within this presentation, we won’t elaborate on fuzz testing as such - but will rather emphasise synergies of fuzz testing with a replayable deterministic program. First, let’s note that strictly speaking, fuzz testing DOES require determinism (but in practice does work without it <wink />). Second, records allow for a very obvious way to implement fuzz testing for your program: as we already have our records which can be replayed and result analysed - they form an ideal substrate for fuzz testing - because fuzz tester such as an afl will be able to mutate the records and to replay them.
As for required type of determinism to achieve replay-based equivalence testing and fuzz testing - it depends. For replay-based equivalence testing to replace outdated implementation - we usually need “Same-platform determinism against minor changes”. For replay-based equivalence testing across platforms - we need full-scale “cross-platform determinism” (though let’s note that for testing environments, unlike for production cross-platform determinism, it is achievable). And for fuzz testing - we’re perfectly fine with same-executable determinism.

However well we’re writing our code, from time to time we’re facing the ultimate nightmare: bug in production. These bugs are traditionally very difficult to reproduce - and can easily live for many years in commercially released code.
The holy grail of production debugging - is to fix bugs from the very first occurrence. To achieve it, ideally - we'd like to reproduce it under debugger.
With deterministic recording/replay, reproducing (and therefore fixing) these otherwise next-to-impossible to identify bugs becomes a breeze: Just record all inputs on the production box - and send them to developers after the problem occurs. BTW, here, “the problem” can be pretty much anything - from core dump, via assertions, and all the way to “user has pressed a button labeled ‘Houston, we have a problem!’”
To achieve this holy grail of post-factum debugging - we need merely a quite-easily-achievable Same-Executable Determinism.
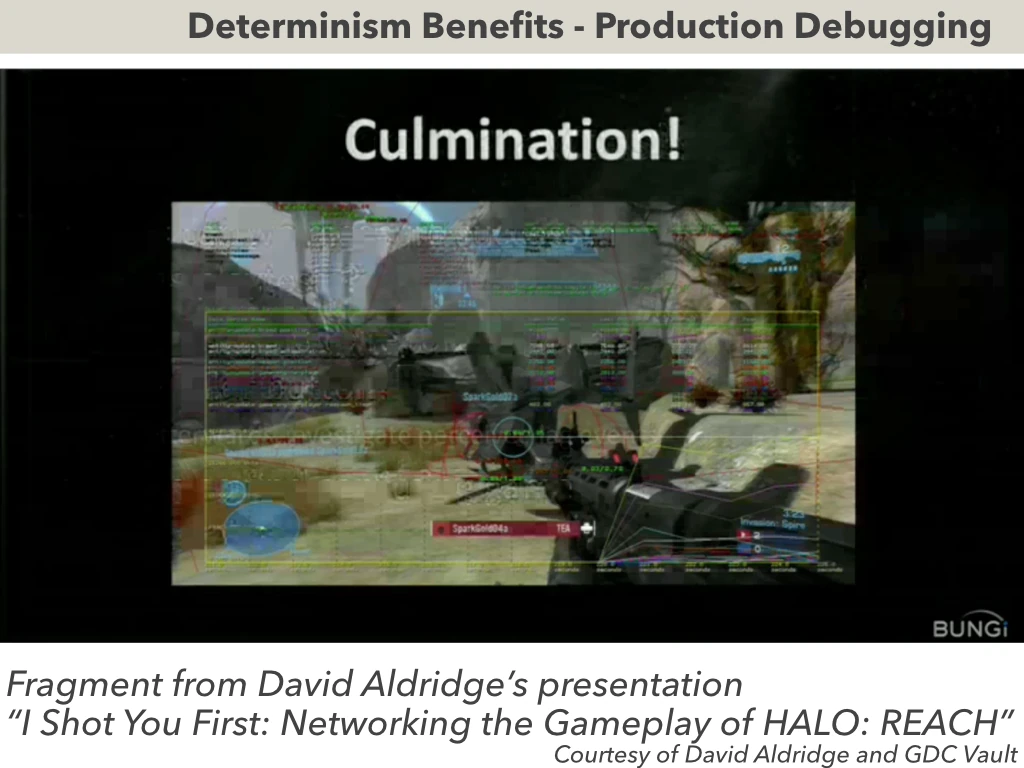
All this stuff may sound as “too theoretical to be of practical use”. To illustrate the power of determinism-based post-factum debugging in a very practical sense, I want to show one real-world video made by a AAA game development company (specifically Bungie) - which illustrates what they managed to achieve.
Very briefly - they had their game deterministic, and for internal playtesting they added a “the game is lagging” button to the game controller. If this button was pressed - record of those input events which lead to this situation - was sent to developers.
And here goes the fragment of this presentation - illustrating the real-world power of determinism and its abilities for production debugging (my apologies for the video quality - multiple re-compressions don’t help it at all, but it should be enough to get the idea).
Here goes a Fragment from David Aldridge’s presentation “I Shot You First: Networking the Gameplay of HALO: REACH” (courtesy David Aldridge and GDC [[for video see GDC Vault presentation around 1:08-1:10; while I was given permission to use it for presentation - I am not sure whether it is ok to use it on the site]]).
I rest my case about determinism-based production debugging being perfectly feasible in practice.

Two even further goodies which can be obtained from determinism, are related to low-latency stuff - more specifically, to low-latency fault tolerance and to low-latency migration of stateful objects.
Low-latency fault tolerance can be achieved via methods which are similar to fault tolerance known as “virtual lockstep” (which was briefly used by VMWare). Very briefly:
- we’re recording inputs all the time (with record including state snapshots)
- record and main object are kept on different physical boxes
- in case of failure - object can be reconstructed from record-with-snapshot
Low-latency migration of stateful objects is a close cousin of the low-latency fault tolerance. It allows to migrate stateful objects from one server to another one (which in turn is often necessary for load balancing and maintenance) - and to do it without incurring the latency cost of serialisation+data_transfer+deserialization.
BTW, let’s note that to achieve both these features - we need merely a relatively-easily-achievable “same-executable” type of determinism.

With all the long list of deterministic benefits, it would be surprising if we didn’t have an “Others” category.
These include at least Deterministic Lockstep and User Replay.
Deterministic Lockstep family of protocols is often used in simulations, including games. The idea is to exchange only the inputs between simulating computers - and that determinism will guarantee that all the instances of the program running on different simulating computers will produce exactly the same result.
When it comes to user replay - we’re primarily speaking about ability to record the game on one device (or Server) - and to replay it on another one.
We need to note, that both these techniques require Cross-Platform Determinism (at least across all the platforms of interest) - and as we’ll see, this is not trivial to achieve.

I hope that by now, I managed to convince you that determinism is a Good Thing(tm). However, all the Good Things in the universe are perfectly useless, unless we know how to implement them (just an example: while it would be very nice to have a “money” button - it hasn’t been invented yet).
To make sure that determinism is practically achievable, now we’ll discuss how to implement those very useful deterministic components.

First of all, let’s make two obvious - but still very important - observations.
Observation 4: Program becomes deterministic as soon as we have eliminated all the sources of non-determinism
Observation 5: As soon as we establish an “Isolation Perimeter” with everything inside the perimeter being deterministic, and recording all the data crossing the perimeter in the “inside” direction - the part of the Program within the Isolation Perimeter complies with our Definition 2.
The point of the latter Observation 5 is to note that we don’t necessarily need to have THE WHOLE program deterministic - but we can have one or more PARTS of our program deterministic - as long as we’re confine these parts into Isolation Perimeters.

Now, let’s take a look at those SOURCES of non-determinism - the ones which we need to eliminate to get to the holy grail of determinism. Here goes a very high-level list:
- Multithreading
- Systems Calls (and most of system calls are non-deterministic; however - allocations might be handled differently)
- Risky behaviours (such as Undefined Behaviours and relying on pointer values), and
- Compatibility Issues (including incompatibilities ranging from CPU to Libraries)
As we can see - there are four broad categories of non-deterministic sources - and to achieve determinism, we need to tackle all four. Fortunately - it is not as bad as it might sound, and we'll try to deal with them one by one.

IMNSHO, multithreading is #1 enemy of determinism. This is not to say that it is not possible to make multithreaded program deterministic - but in case of multithreaded programs, we need to PROVE that each inter-thread interaction doesn’t cause non-deterministic behaviour.
Let’s note that from the point of view of pure electronics - and as long as we’re staying within the same “clock domain” - it IS possible to build perfectly deterministic systems. However, the way how existing software is built (starting from operating system level) - inter-thread interaction is not deterministic at all. There are lots of different factors which will affect exact inter-thread timings - starting from interrupts, and ending with cache evictions caused by concurrent processes. And without being able to reproduce exact timings - we cannot guarantee that the end result will be exactly the same.
Once again - I am not trying to say that multithreaded deterministic programs are impossible - but, unless a very straightforward paradigm is in place - they’re EXTREMELY difficult to produce.

My by far favourite way to deal with multithreading is by using (Re)Actors. They are known under several different names: Actors, Reactors, ad-hoc FSMs, and Event-Driven Programs. To avoid confusion with other similar-named but very different concepts (such as “reactive programming”) I prefer to spell them as shown on the slide: bracketed-“Re” followed with “Actor”.
Under (Re)Actor, I mean a good ol’ program which treats everything as an incoming event - and merely processing these events as they are coming, ALL WITHIN ONE SINGLE THREAD (or at least “as if” it is one single thread).
(Re)Actors are very straightforward, very familiar to developers, and tend to perform very well (I won’t go into lengthy discussion here, but there ARE reasons why nginx beats Apache, and why Java guys - after 6 years of saying that multithreading it THE way to write programs - eventually did introduce non-blocking I/O back 15 years ago).
As for (Re)Actor scalability - contrary to popular belief, they CAN scale; while scaling (Re)Actors can become a non-trivial exercise - I will argue that scaling ANY architecture is non-trivial. Moreover - as (Re)Actors follow Shared-Nothing paradigm, it means that after initial scaling effort - they scale in an almost-perfectly linear manner (and linear scaling is next-to-impossible to achieve for real-world mutex-based multithreaded architectures).
From a real-world perspective - I’ve seen purely (Re)Actor-based systems processing billions of user requests per day - and making dozens of millions of DB transactions per day - with an ability to scale further.
Most importantly for us - (Re)Actors lend themselves to deterministic programs really well. In particular - they do NOT introduce any non-determinism themselves (so as long as other three sources of non-determinism are eliminated - we’re fine). In addition - they provide a very natural way to record all the input events (we’ll discuss it in a moment).
As a result - for the rest of this presentation, we’ll discuss how to implement deterministic (Re)Actors; while alternative architectures which allow to deal with MT in deterministic manner DO exist (in particular, other message-passing architectures which are not (Re)Actors, exhibit very similar properties) - you will need to prove their correctness yourself.

As we’ll be speaking about (Re)Actors quite a bit - let’s establish some basic terminology which we’ll use.
Let’s name Generic Reactor a common denominator for all our (Re)Actors. As we can see, Generic Reactor just an abstract class - and has a pure virtual function react().
Let’s name “Infrastructure Code” a piece of code which calls Generic Reactor’s react(). Quite often - this call will be within so-called “event loop” as shown on the slide.
As we can see - there is one single thread, so there is no need for thread synchronisation within react(); this is very important for several reasons (including coding being straightforward and avoiding cognitive overload) - but for our current purposes, most importantly, it means that we do not introduce non-determinism.
Let’s also note that get_event() function can obtain events from wherever-we-want-to - from select() (which is quite typical for servers) to libraries such as libuv (which are common for clients).
And finally, let’s name any specific derivative from Generic Reactor (which actually implements our react() functon) - a Specific Reactor.
I need to note that a virtual-function-based implementation above is not the only one possible - for example, the same thing can be done using templates instead of virtualisation - but for the purposes of our examples, we’ll stick to this one.

In our previous examples - there was no recording in sight, so - while (Re)Actor was potentially deterministic - there wasn’t a way to exploit this determinism. Let’s see how recording/replay can be added to our (Re)Actors.
One way to implement recording/replay is shown on the slide. Here, we have two separate loops - one is recording loop (which is run during normal operation), and another is replaying loop (which is run only during replay).
For our implementation, we’ll assume that we record to a so-called “inputs-log”, which consists of “frames” - each of the frames being just a self-contained unit of serialised data.Within Recording Loop, we’re just writing frames into inputs-log for each of incoming events (with each log frame being just a serialised event).
Within the Replaying Loop - we’re reading inputs-log frames, deserialising events from them - and feeding the events to react() function. It is indeed this simple. And as long as our (Re)Actor is indeed deterministic - it will produce exactly the same results during recording and replay.
As a side note, let’s observe that recording/replay logic is very self-contained, which means that they can (and usually should) be implemented as (Re)Actors themselves - which makes them independent from Infrastructure Code.

How to implement the inputs-log itself - is a relatively minor implementation detail; however, there is one practical consideration which is very important for real-world systems.
If we just write all the frames to the inputs-log with all the events - it means that we’d need to store ALL the events starting from the very creation of the (Re)Actor. However - for anywhere-seriously-loaded real-world systems this is rarely practical (just because inputs-log will grow too large, replay will take too long, and so on).
To address this issue - circular inputs-log is usually used. The idea with circular inputs-log goes along the following lines: we have some pre-allocated space for the inputs-log, and as soon as inputs-log goes close to the space limit - we serialise state of our (Re)Actor into the inputs-log, and keep writing input events after this serialised state. Then, to reconstruct our (Re)Actor - we can always take serialised state, and replay all the input events which came in after serialization.
Of course, serialisation may require significant time - but as long as it is done only occasionally, it is not too bad. And if latencies caused by serialisation, start to cause trouble - it is usually possible to organise incremental serialisation (storing each of the increments within a separate inputs-log frame).
Last but not least - such a circular inputs-log can be kept in-memory, and used only when some problems are detected (such as crash, assert, or user pressing “the game is lagging” button). Obviously, keeping logging in-memory-only tends to speed things up very significantly.
With our (Re)Actors and Circular Inputs-Log (and assuming that (Re)Actor itself doesn’t create threads) - we have eliminated the first major source of non-determinism - multithreading.
Now, let’s see what can be done with the other three sources. The next one on our list is System Calls.

System calls is one very significant source of non-determinism in programs. Pretty much everything returned by system calls cannot be derived from the caller state (a few exceptions, but we can ignore them for now).
This includes:
- I/O
- time and similar functions
- real RNG
- and so on
However, for the purposes of ensuring determinism I suggest NOT to treat memory allocations (mAlloc(), VirtualAllocEx(), mmap(), etc.) the same way as other system calls - and to avoid relying on specific pointer values instead. In other words - I am suggesting to treat memory allocations separately - and under “Risky Behaviours” section.
On the other hand - it is only a matter of performance, and strictly speaking - “call wrapping” described below, will work even for allocations.

The first (and a very very universal) technique to make system calls deterministic, is to “wrap” system calls, making these “wrapped” versions deterministic. Let’s consider our original non-deterministic example.
Here, the most trouble comes from the line where we call function time() (strictly speaking, localtime() also can be a source of non-determinism - but it can be handled in an exactly the same manner).
Let’s take this single non-deterministic line of code and see how it can be made deterministic.

To handle our non-deterministic line calling system function time() in a deterministic manner - we merely need to replace it with our own function such as my_time(); all the magic will happen within my_time().
When our program is run in recording mode - my_time() will simply record all the values-it-got-from system call, and write them (as a special frame) to the same inputs-log where all our events are written.
And when our program is run in replay mode - we do not call time() at all, reading the value from the inputs-log instead. That’s it, it is indeed THIS simple.
BTW, we can (and usually SHOULD) write function parameters to inputs-log too; while this is NOT necessary to achieve determinism - it DOES come handy to double-check that behaviour is indeed deterministic (and to identify problems as soon as possible).

Actually, the most interesting part of the call wrapping is not really code - but the following observation on which call wrapping is built upon: Due to deterministic nature of our program, all the calls will happen in exactly the same places in relation to input events and other calls, so whenever my_time() is called during replay - there will be a corresponding inputs-log frame waiting for us at the current position within the inputs-log.
Formally - position of the my_time() frame within the inputs-log is a function of the previous inputs and return values of the previous calls, and as long as this function is deterministic - position is deterministic too
.
“Call Wrapping” which we’ve just discussed, is a very powerful tool; its main advantage is that it can handle ALL the system calls. The only exception is related to functions which return pointers - but these are rare and can be usually wrapped into pointerless versions before using “call wrapping”. As for the handles - they can usually be ignored in the same manner as other return values.
Overall, “call wrapping” works well for Same-Executable Determinism; however - if we go beyond single executable and want to use our (Re)Actor for Replay-Based Regression Testing or for Equivalence Testing - in certain cases it may start to cause trouble. The problem with call wrapping when used to slightly-changed but supposedly-equivalent code, is the following. If two versions which we’re comparing, are calling the same function more than once to get (almost) the same result - the whole thing can be equivalent, but sequence of calls will be different, and our testing based on the Call Wrapping will fall apart.

Most commonly, this latter problem happens with functions such as time() (GetTickCount(), gettimeofday(), and so on). Let’s take a look at the following (admittedly very artificial) example.
First, we had a Version 1 of our program, which has had two calls to my_time() function. And then - we�’ve optimised it into Version 2. This is a very common refactoring scenario - so we need to know how to handle it (at least if we want to use Equivalence Testing or Replay-Based Regression Testing).
If we’re using “Call Wrapping” to implement my_time() - and will try to run Equivalence or Replay Testing over Version 1 and Version 2 - then our testing will fall apart - just because in version 1 there are TWO frames for my_time() call, and in version 2 there is only ONE such frame.
Moreover, it is NOT just a false positive, but actually an acknowledgement that these two versions are indeed different - because in Version 1 two calls MAY return different values once in a blue moon. On the other hand - in 99.99% of the cases, from developer’s point of view, these programs are the same.

One way to deal with this problem, is to say that time is not obtained via my_time() - but is rather a constant field of Event object - which is pre-populated for each event.
An equivalent alternative is to have an different implementation of my_time() - which merely reads current event time from the thread-local storage.
Whatever the exact technology is used - these two implementations will lead to EXACTLY the same results (the only difference is purely syntactical one). Essentially - both these implementations PRE-CALCULATE result which might be necessary for (Re)Actor - and provide it just in case.
What’s more important - both these implementations make our determinism IMMUNE to optimisations which we described before (and for a good reason too - with both these implementations, Version 1 and Version 2 on the previous slide become EXACTLY equivalent).
In general, I DO prefer one of these approaches to Call Wrapping for time-like functions. Let’s just note that with these Pre-Calculation-based implementations in mind, we will NOT be able to measure things such as “how long this function is running”; for these relatively rare cases - Call Wrapping should be used instead.

Another case when Call Wrapping is not exactly the right way to handle System Calls - is for calls which take considerable time; as a Big Fat Rule Rule of Thumb(tm) - within (Re)Actor model such LONG calls should be made non-blocking.
This is a requirement which doesn’t really come from ensuring determinism - but from overall preference for non-blocking I/O which is common for (Re)Actors. On the other hand - it does come handy for determinism purposes too. As long as return value is passed via an Event - it will be recorded just as any other Event, so nothing special needs to be done about it to ensure determinism.
Let’s also note that the non-blocking version shown on the slide, is by far not the only way to express handling of non-blocking returns in (Re)Actors; in particular - in Chapter 5 of my upcoming book (which I will refer to at the end of this presentation) - there are EIGHT different ways of handling non-blocking calls in (Re)Actors - ranging from simplistic event-based handlers like the one shown here, to lambda-based code constructors and co-routines.

Call Wrapping essentially covers all the non-determinism coming from System Calls; however - in some cases, it might be better to use Pre-Calculation (and for Non-Blocking Calls - there is no need to use Call Wrapping to start with).
Whatever techniques we’ll be using in specific cases - such techniques DO exist. It means that we’re done with two out of four major sources of non-determinism, and have two more to go.
The next one on our list is Risky Behaviours.

In general, Risky Behaviours usually result from one of the following:
- Undefined Behaviours
- Using unsupported inter-thread communications , or
- Relying on pointer values.
Undefined Behaviours (such as reading uninitialized memory, violating strict weak ordering forSTL containers, etc.) are the easiest ones - we should avoid them regardless of determinism, that’s it.
Unsupported inter-thread communications is the next thing on the list of things to be avoided. This one is pretty easy to avoid, provided that we remember not to use non-const globals.
The third one - relying on pointer values - is a quite nasty problem, and it may result in perfectly-valid programs which are not deterministic. One example of it is the case when we want to have just SOME kind of sorting for on-heap objects; in this case we could use pointer to an object as a sorting key - and it will work, but it can easily result in non-deterministic behaviour between different runs of the program (even more so if something like ASLR=Automated Space Layout Randomization is used). Another similar example is using pointers as IDs.
In general - to avoid relying on pointer values - we MUST NOT use pointer for ANYTHING except for dereferencing (or accessing element of an array for that matter). However, as soon as we limit ourselves to dereferencing-only - we’re perfectly fine.
Let’s also note that most of the time, problems resulting from relying on pointer values can be avoided entirely by “wrapping” malloc() calls (and guaranteeing stack location) - but this is usually too expensive and cumbersome for practical use. Usually it is still better to avoid reliance on pointer values instead - and it usually won’t cause too much trouble in practice.
Overall, the main problem with Risky Behaviours is not how to handle them - but how to identify what’s risky and what’s not. However, while they do take some time to figure out - they are usually caught pretty quickly, and get fixed even more quickly. Sure, they will take some time to deal with - but not too much.

As we just discussed - Risky Behaviours can be avoided without too much trouble.
Which leaves us with the only thing to deal with - it is Compatibility Issues.

Compatibility Issues arise at least from three different sources - CPU, compiler, and libraries.
CPU-related differences can be pretty much anything - from a non-IEEE implementation of floating-point math, to different handling of misaligned memory accesses. Oh, and let’s not forget about those Intel-CPUs-with-FDIV-bug.
Compiler-related differences vary even more - and can easily break lots of programs which exhibit deterministic behaviour under Same-Executable Determinism model. To make things worse - even compiler options can EASILY make or break determinism.
In addtion, one the worst Compatibility Issues will be related to libraries you’re using. In particular, C++ std library doesn’t specify quite a few behaviours - and you can easily fall victim of them. Just one example - if you’re putting different elements with the same key into your std::multimap<> - then iteration order over the multimap<> is not guaranteed, and can easily depend on implementation specifics of your library.

One special (and particularly nasty at that) case of Compatibility Issues affecting determinism - is floating-point determinism. While for the same executable floating-point determinism is quite easy to achieve - as soon as Compatibility Issues come into play, it can become an insurmountable task very quickly. Two big obstacles on the way of achieving cross-platform floating-point determinism are evaluation order and libraries.
Evaluation order is a problem because first, floating-point addition is not associative due to implicit non-linear rounding operation inside - and at least C/C++ compilers tend to shuffle order of calculations very freely; moreover - nothing prohibits C/C++ compiler to store intermediates in larger-precision registers on certain platforms - and this can easily affect the end-result too.
Even worse are floating-point library functions such as sin() - you will be really lucky if two libraries on different platforms will return EXACTLY the same results for ALL possible input values.

When speaking about Compatibility Issues affecting determinism - it is necessary to note that they depend significantly on the programming language used. In particular:
- for C/C++, situtation is pretty bad, because of:
- LOTS of UB
- floating point is a nightmare (As compiler can rearrange things at will - making floating-point code deterministic, while often possible, is pretty bad for C/C++)
- And last but not least - C/C++ library standards tend to leave lots of leeway for library implementors; while it is supposedly good for performance - it is certainly bad for determinism.
- for Java - things are significantly better, because of:
- much more rigid behavior prescribed wiithin standard
- strictfp for floats
- still, some of the libraries need care (In particular, last time I’ve checked, Object.hashCode() was not deterministic, and as a result, quite a few libraries which use hashes - weren’t deterministic either)
- As for the other programming languages - Compatibility Issues depend heavily BOTH on language AND on implementation specifics. For example, for Python, as long as we’re using CPython - things aren’t too bad (except for hashes); but if we’re speaking about Compatibility between CPython and Jython - we’re risking very severe and potentially unsolvable problems.

On the positive side, Compatibility Issues are completely non-existing for Same-Executable Determinism (which is enough to have MOST of the deterministic goodies). Phew.
For Equivalence Testing and Replay-Based Regression testing scenarios across different platforms (or across different versions of the compiler/library) - Compatibility Issues will take their toll, but are usually not that difficult to handle. What saves us is that even in case of the most nasty floating-point ordering problems - when we’re testing, usually we can easily change the order of the NEW code to be exactly the same as behaviour for the OLD code (by inserting parentheses, splitting the line into two, and so on). Note that this wouldn’t fly if we RELY on the order to be EXACTLY the same ALL THE TIME IN PRODUCTION - because non-determinism will certainly find a way to hurt us when we’re not looking.
As a result - for full-scale Cross-Platform Determinism - Compatibility Issues can cause HUGE amounts of trouble (especially if using C/C++). Moreover, in case of massive floating point calculations - they were observed to kill the whole idea of achieving Cross-Platform Determinism (note that if floating point calculations are only accidental - there is always an option to use software floating lib such as SoftFloat, which will allow to make your program deterministic).
On the other hand - we rarely need full-scale Cross-Platform Determinism (that is, unless we want something exotic such as Deterministic Lockstep). Most of the time - we’ll need to deal with either Same-Executable Determinism (where Compatibility is not an issue), or with Equivalence Testing/Replay-Based Regression Testing scenarios - where determinism is usually achievable.
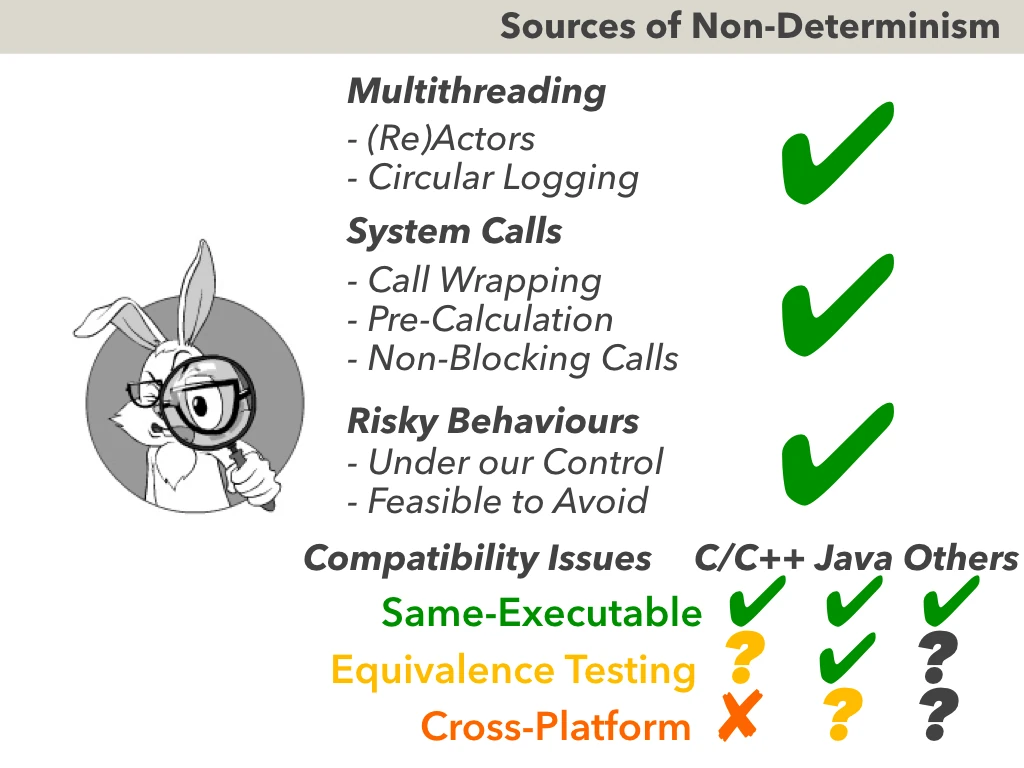
To summarise our findings about Compatibility Issues (and about creating deterministic programs as a whole):
- Same-Executable Determinism is perfectly achievable
- Determinism for the purposes of Equivalence Testing across different platforms - is admittedly a headache for C/C++, but at least it is usually achievable; for Java - it is substantially simpler, and as for other languages - it depends on the language.
- However, if we’re speaking about full-scale Cross-Platform Determinism (especially if heavy floating-point calculations are involved) - then Compatibility Issues will cause lots of trouble, up to the point of full Cross-Platform Determinism becoming potentially unfeasible for C/C++. Fortunately enough, such a full-scale Cross-Platform Determinism is rarely needed in practice.

In addition to sources of non-determinism, there are a few issues which are often mistakenly SEEN as such - but which are not really interfering with determinism.
Such non-issues include:
- PRNGs. PRNGs are perfectly deterministic in spite of PRETENDING to be random. To make them LOOK really random for outside world - it is usually sufficient to (a) get a really random seed once, and (b) to use a simple fast crypto-strength PRNG (such as AES in CTR mode) - to get the pseudo-random data. Such a construct will be very fast - and impossible to predict from outside too, all while staying perfectly deterministic (as soon as that really-random seed is recorded in one of the ways we discussed above).
- Text logging/tracing. As long as usual text logging stays write-only (i.e. we’re not trying to read our own text logs from within our program) - it is deterministic without any special measures to ensure determinism. Moreover - if you have Node.js-style time() and timeEnd() functions - which call time() and then write current time to the text log without returning it, it is perfectly fine to implement them WITHOUT call-wrapping call to time().
- Caching. Caching is a bit special in this regard, but in general - caches can be either treated as a part of the deterministic program - or treated as residing “outside” of our deterministic program. In this second case - we’re placing our “Isolation Perimeter” between the program and the cache; from practical perspective - it can be useful to reduce the size of the program state (which is important, as for circular logging, program state needs to be serialized).

By now, we discussed benefits out of having deterministic components - and the way how to implement them.
However, what we didn’t discuss (yet) - is how to COMBINE these deterministic components to make an interactive distributed system out of them.

First of all, let’s define what are those Interactive Distributed Systems which we’ll be speaking about.
As advertised - they are distributed and interactive. In particular - “distributed” means that the system is built from components, where:
- components are usually stateful
- communicate via messages
And “interactive” means that usually, we're dealing with typical response times are from single-digitmilliseconds to single-digit seconds.
BTW, let’s note that we’re speaking about “Distributed Systems” - and are NOT telling that these systems should be necessarily deterministic as a whole.
Examples of such Distributed Interactive Systems include:
- Multiplayer Games
- these include stock exchanges and auctions
- Any Reasonably Complex Device
- including laptops, smartphones, TVs, etc.
- Internet as a whole
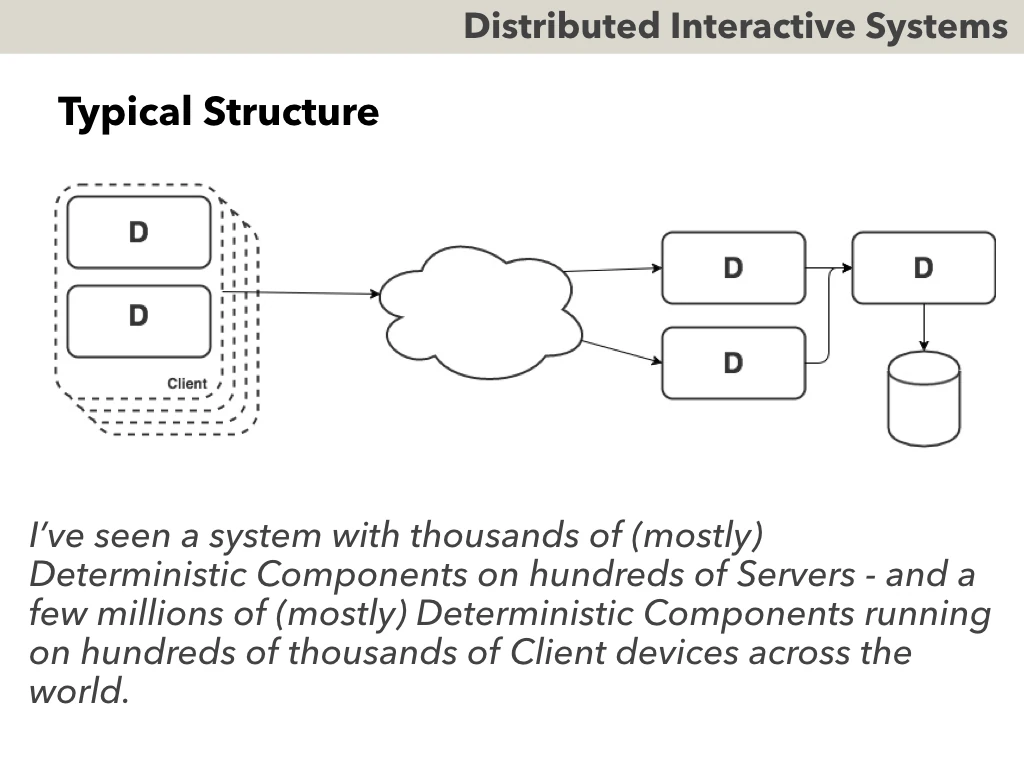
For business-oriented Distributed Interactive Systems - Deterministic Components can be used at least on Server-Side. Here, “D” denotes “Deterministic Component”. However, we MAY use them on the Client too.
In real-world, I’ve seen a system with thousands of (mostly) Deterministic Components on hundreds of Servers - and a few millions of (mostly) Deterministic Components running on hundreds of thousands of Client devices across the world.

I’ve spent quite a bit of time working on interactive distributed systems (mostly games - though including stock exchanges too). And looking from this experience, I can say that one of the biggest challenges with such Interactive Distributed Systems is debugging and testing.
Moreover - for such systems, at least 80% of the bugs which make it into production - tend to be bugs which are related to unusual sequences of incoming events. Such bugs are especially nasty, as we cannot predict them in advance - and therefore cannot test them either.
It is unbelievable how many different sequences of events can be produced by one hundred thousand of users pressing buttons simultaneously. In one of the companies with hundreds of thousands of simultaneous users - standing Rule of Thumb was that “if new release didn’t crash during first 4 hours after deployment - it won’t crash at all”. This is not to say that the system crashed often (it was crashing at least 3-5x less frequently than the rest of the industry) - but to illustrate that however-well-you-are-testing - you cannot possibly match hundred of thousand of usual users.

Now let’s see how Deterministic Components help to solve this Really Big Problem.
First of all, they improve overall testability. In particular:
- if we have a problem - we can reproduce it, and reproducible bug is a dead bug
- In addition, it helps to fix bugs found during simulation testing, MUCH faster - and simulation testing tends to be very important for testing of distributed systems.
Also - Deterministic Components allow for Replay-Based Regression Testing (and if we take inputs-logs from production - we can be sure that we did re-test MOST of the real-world event sequences - including THOSE SEQUENCES WE KNOW NOTHING ABOUT).
And last but certainly not least - if a bug has managed to slip into production (which is bound to happen from time to time for any business-oriented system) - post-factum debugging allows to identify and fix it from the very first reported crash, over EIGHTY PERCENT OF THE TIME. This kind of performance is outright impossible without at least some level of determinism.
I’ve seen (and actually built) several Distributed Interactive Systems made out of Deterministic and mostly-Deterministic components, and they exhibited very good properties. In particular, they had 3-to-5 times less unplanned downtime, than industry averages. Of course, it can count only as an anecdotal evidence - but as we have BOTH theoretical reasons WHY Deterministic Components are good, AND some anecdotal data to support this theory - there MIGHT be something real behind these anecdotal observations.

As a side note, let’s observe that while I am strongly arguing for using Deterministic Components - I am NOT saying that the the whole Distributed System must always be deterministic.
Let’s note that:
- System built from Deterministic Components in not necessarily deterministic as a whole
- Moreover, unless special measures are taken - more often it is NOT deterministic
- On the positive side, most of the time - it is NOT a problem in practice
- Making the whole System deterministic is equivalent to establishing one single time for all the Components.
- To do it - several methods exist, including CMS/LBTS protocols, and “rewind” techniques similar to both financial “value date” and gaming “Server Rewind”. Unfortunately, we're running of time - but some references on it can be found in Chapter 3 of my upcoming book.

We’re almost done, and now are in position to summarise the whole over-an-hour presentation into one single slide:
- Deterministic Components improve system quality significantly, via:
- improved debugging
- improved testing (including Replay-Based Regression Testing)
- production post-factum debugging
- Deterministic Components are achievable, via:
- (Re)Actors (or a reasonable facsimile)
- Circular Logging
- “Call Wrapping” and a few other techniques
And last but certainly not least, all these arguments lead us to an inevitable question - WHAT ARE YOU WAITING FOR? GO AHEAD AND IMPLEMENT YOUR NEXT DISTRIBUTED SYSTEM ON TOP OF DETERMINISTIC COMPONENTS! <smile />

To wrap it up, I also have to note that the subject of the determinism (especially when speaking about fine details of implementing it) is quite large. As a result - it isn’t possible to fit all of this discussion into one 90-minute presentation, so pretty much inevitably there will be remaining questions. For further information, you can either e-mail "No Bugs" at [email protected], or you can wait for Vol. II of his upcoming book on “Development & Deployment of Multiplayer Online Games” (Vol. II is scheduled for print in about two months). In Chapter 5, he discusses deterministic implementations in the context of event-driven programs - and it took him over 40 pages to do it. BTW, I happen to have a few printouts of the current draft of this whole Chapter - so if you’re interested - you can take one of them.
We're done now, so if there are any questions which weren't asked during the presentation - please feel free to ask them now.


Comments